ARM Optimized Motion Estimation
This project was done for an Embedded Systems class - SENG 440 at UVic.
Skills
- Computer architecture (ARM Processors)
- Parallel computing (SIMD & Neon Intrinsics)
- C, Assembly & Python
- Embedded
- Algorithms
Background
The goal of this project was to optimize the “sum of absolute differences” (SAD) operation. This operation is commonly used to compress videos. The general idea is to find regions in a video frame that are much different than the preceding frame. This way only changes from frame to frame are encoded instead of the entire frame itself as often most of the frame is extremely similar. This greatly improves memory and speed when encoding video:
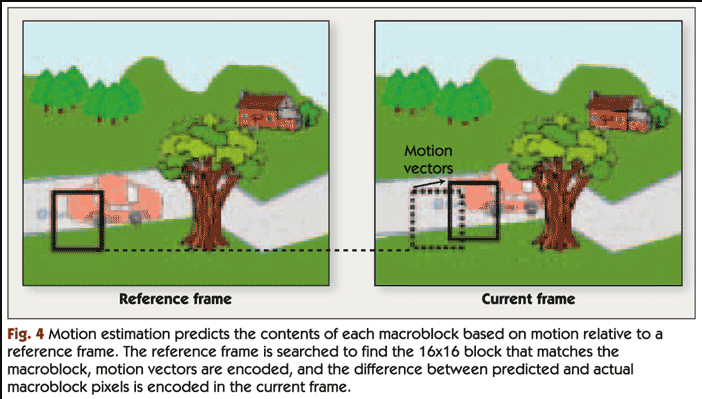
from: https://www.eetimes.com/how-video-compression-works/
Implementations
A few different approaches were taken for this problem:
- Software optimizations
- Hardware based optimizations
Hardware based optimizations
The idea here is to utilize the single instruction, multiple data (SIMD) capabilities of ARM based chips. When computing SAD, the data can be packed into two SIMD vectors and the SAD can be computed 2-4x faster in parallel instead of having to loop through each vector element individually:
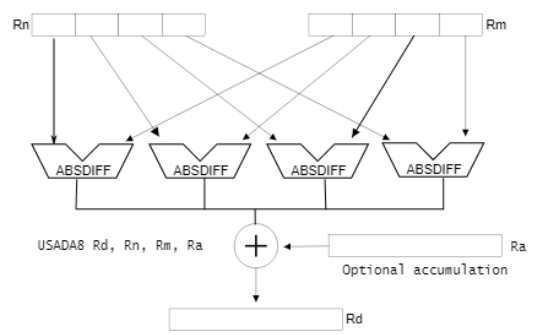
This was implemented in two ways: a Non-reentrant solution (meaning there is no global state and it is safe for simultaneous/threaded execution) and a reentrant solution (state is kept track of with a shared global variable)
This snippet comes from GitHub.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
int hw_sad_nonreentrant(uint8_t *__restrict blockA, uint8_t *__restrict blockB) {
uint8x16_t result;
uint8x16_t v_blockA;
uint8x16_t v_blockB;
// Load 16 size 8-bit into SIMD register
v_blockA = vld1q_u8(blockA);
v_blockB = vld1q_u8(blockB);
// Absolute difference between the two vectors
result = vabdq_u8(v_blockA, v_blockB);
// Split the 16x8 result vector into two 8x8 vectors
uint8x8_t result_low = vget_low_u8(result);
uint8x8_t result_high = vget_high_u8(result);
// Sum the lower and upper halves of the result vector
uint8x8_t acc = vadd_u8(result_low, result_high);
uint16x4_t acc1 = vpaddl_u8(acc);
uint32x2_t acc2 = vpaddl_u16(acc1);
// Calculate the total
uint32_t sum = vget_lane_u32(acc2, 0) + vget_lane_u32(acc2, 1);
// Return the total as an integer
return (int)sum; }
The highlight of this code is the vabdq_u8 instruction. This calculates the unsigned absolute difference between two vectors and returns the result. In the regular software version this part takes n calculations for a vector of length n.
The reentrant solution is much simplier:
1
2
3
4
5
6
7
8
9
10
11
12
void hw_sad_reentrant(uint8_t *__restrict blockA, uint8_t *__restrict blockB, uint8x16_t *v_acc) {
uint8x16_t v_blockA;
uint8x16_t v_blockB;
// Load 16 size 8 bit into SIMD register
v_blockA = vld1q_u8(blockA);
// Load 16 size 8 bit into SIMD register 2
v_blockB = vld1q_u8(blockB);
// absolute difference between the two vectors + accumulate
*v_acc = vabaq_u8(*v_acc, v_blockA, v_blockB);
}
With SIMD summation done at the end of each 16x16 block, integer addition is done 15 times less which amounts to 25x15 = 375 saved instructions per 16x16 block
Less looping and branching also means less cache and branch misses which greatly improves performance.
HW Improvements:
The current bottleneck is packing vectors into SIMD registers. This takes 16 instructions and no computations can be done untill the two vectors are completely packed. A future improvement could be starting to pack the next two vectors (pixel rows) at a 2 cycle offset. This matches the amount of cycles it takes to compute the SAD so after a calculation is done the next two vectors are already packed and ready to go:

Software Optimizations
This was not a very productive approach as gcc already does an amazing job optimizing code when compiled. The methods implemented were:
- Loop unrolling
- Miscellaneous optimizations (predicates, reducing number of branches)